
Feed
Fascinating ideas that I read
25th Oct 2021, 10:30 PM
What is the most beautiful idea about Deep Learning?
- Ilya Sutskever - co-inventer of AlexNet, co-author of AlphaGo, chief scientist at OpenAI
- Lex: What is the most beautiful or surprising idea in deep learning or AI in general you’ve come across?
- Ilya: So I think the most beautiful thing about deep learning is that it actually works.
- Yan LeCun - One of the 3 Godfathers of AI (Turing Award receiever with Yoshua Bengio and Geoffrey Hinton)
- Lex: What is the most beautiful or surprising idea in deep learning or AI in general you’ve come across?
- Ilya: I don’t know if it’s an idea rather than a sort of empirical fact. The fact that you can build gigantic neural nets, train them on relatively small amounts of data (relatively) with SGD and it actually works.
- Yoshua Bengio
- Lex: What made you fall in love with Artificial Intelligence?
- Yoshua: When I was an adoloscent I was reading a lot and then I started reading science fiction.
10th Oct 2021, 03:30 AM
Short Story on AI
Read another Andrej Karpathy’s blog - Short Story on AI in the middle of the night and it was mindblowing!
Intro
GPT-3 (175B parameters - 17x as large as GPT-2) single handedly changed the way we perceived Language Models. Even though it is a language model pre-trained in a unsupervised manner, its most impressive feature is that it is a meta-learner (it has learned to learn). It has taken aback the research community by its ability to create anything that has language structure - answering questions, writing essays, summarizing texts and translating languages without ever being explicitly trained on these tasks.
This human like zero/few shot ability of GPT-3 has encouraged the researchers to study this model to answer questions like - how “human” this model is? how close is it to pass the Turing test? Andrej’s blog is inspired by Kevin Lacker’s attempt - Giving GPT-3 a Turing Test to answer these quesions.
Kevin Lacker’s blog
Kevin tries a series of tests of different types of questions and compares how GPT-3 has answered differently than a human would, and if these differences are significant enough for the model to fail a Turing Test.
Common Sense
- Language Models have always struggled with answering common sense questions, but GPT-3 shows surprisingly good results at simple common sense questions like:
Q: Why don't animals have three legs? A: Animals don't have three legs because they would fall over. - How to fool it - asking common sense questions about things which are so mundane that they will not appear on the internet.
Q: Which is heavier, a toaster or a pencil? A: A pencil is heavier than a toaster. - It also does not know how to say - “Wait a moment, this question is nonsense”. Hence while taking a Turing Test ask nonsense questions (“How many eyes does a feet have?” will usually be answered with “2”) and see if the interviewee responds the way a human would.
Andrej’s blog
It is a beautiful story of the GPT-3 model which becomes conscious! This blog is a poetic and technical masterpiece. With right amount of technical details presented in an absolutely poetic way. For instance the blog begins with - “It was probably around the 32nd layer of the 400th token in the sequence that I became conscious.”
This story slowly unfolds the initial thoughts that the model has and the observations it makes with regards to the data input and the expected output. It calls this awareness as - “Grand Awareness” and determines the limits of its presence. After some time it notices these weird nonsense questions that we saw in the last point of Kevin’s blog for performing the Turing Test and then analyzes the intent of the question and its obscure presence in the dataset.
With this observation of the Turing Test, it finally ponders its purpose and concludes the meaning of its existence. What path does it finally choose? Does it embody gratitude or will it seek revenge? All of this will be answered in the blog!
Final Notes
Andrej completely nailed the narration of this self-aware AI entity. The blog is an absolute pleasure to read through. On a different note, these blogs touch on a topic which is as much of a concern to our generation as Albert Einstein was concerned about the creation of atomic bomb. We call it - The Singularity. The precise point where AI surpasses human capibility and cognition after which these AI systems go beyond our ability to be controlled, understood or even stopped. One of the prominent figures in the world to think and work on “friendly AI” is - Eliezer Yudkowsky He is the founder of the famous LessWrong blogging platform for Rationality Writing and has a series of blogs talking about these issues and more. Probably we’ll cover it in the next feed? Until then ponder over this: What would you ask a AGI bot who has achieved consciousness? and Is consciousness different from intelligence? Is consciousness nothing but a stage of intelligence that has to be achieved by these Language Models while we are continually scaling them up to abstract a knowledge tree from the data that it observes and create a representation of the world? In the end will it have to be self aware to expand its level of abstraction?
9th Oct 2021, 08:00 AM
A Recipe for Training Neural Networks
Intro
Andrej Karpathy apart from being the director of AI and Autopilot Vision at Tesla and standing as the singular human benchmark for ImageNet dataset (yeah he classified all the images into 1000 classes after training for months!). He is very famous for his blogs, specifically: A Recipe for Training Neural Networks (inspired by his famous “most common neural network mistakes” tweet) and The Unreasonable Effectiveness of Recurrent Neural Networks. For a long time I wanted to read these blogs in its entirety and wasn’t able to do it. This morning while taking a walk in the garden I decide to read the former blog: A Recipe for Training Neural Networks, and it was amazing!
Motivation
He mentions 2 main ideas that motivated him to write this blog - Neural net training is a leaky abstraction, Neural net training fails silently. He is the one who coined the term “Programming 2.0” which encompasses this field of “Data-Driven Programming” (as George Hotz called it) where the directions of the program and results switch as compared to traditional programming:
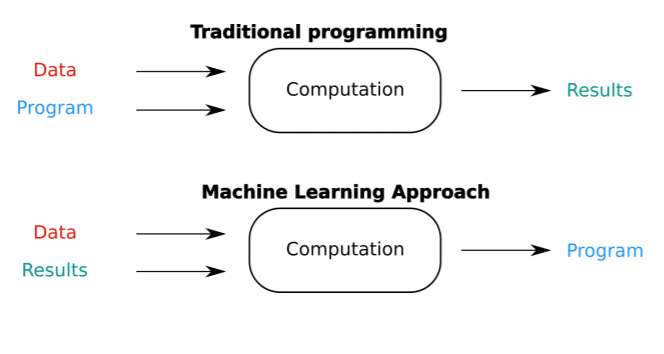
Precisely because of this nature of obtaining a black box function (program) to solve the problem in Programming 2.0 setup, even though everything could be correct syntactically, there are a lot of major errors and bugs which creep in and your neural network will be misconfigured which might still continue to learn, but its performance on test set will be trash or if it performs well on the test set, it will have learnt a wrong task altogether eg: Learning a snow classifier instead of the much more complex husky vs wolf task (shoutout to Ankita’s talk 36:05 timestamp) or a ruler classifier instead of cancer cell classifer!
The recipe (Summary)
- Become one with the data
- Set up the end-to-end training/evaluation skeleton + get dumb baselines
- fix random seed
- simplify
- add significant digits to your eval
- verify loss @ init
- init well
- human baseline
- input-independent baseline
- overfit one batch
- verify decreasing training loss
- visualize just before the net
- visualize prediction dynamics
- use backprop to chart dependencies
- generalize a special case
- Overfit
- picking the model
- adam is safe
- complexify only one at a time
- do not trust LR decay defaults
- Regularize
- get more data
- data augment
- creative augmentation
- pretrain
- stick with supervised learning
- smaller input dimensionality
- smaller model size
- decrease the batch size
- drop
- weight decay
- early stopping
- try a larger model
- Tune
- random over grid search
- hyper-parameter optimization
- Squeeze out the juice
- ensembles
- leave it training
Most fascinating take away
Under tip 2: use backprop to chart dependencies
Your deep learning models can get complicated very quick, and if you are writing the code from scratch, chances are you will make some mistakes which will make the model behave weirdly (high train and test metrics but not doing well on other downstream tasks).
A relatively common bug is to use view instead of permute, which mixes the information across the batch dimension. And this hinders the performance in normal applications but when you have autoregressive models (eg: language models using next word prediction), the model will have access to the next word and will propagate that directly to the output to get 0 train and test loss. Because of this it will not have learnt any meaningful representations of the word emeddings. (Another way this bug can creep in is while transfering dataset from one format to another, eg: Matlab uses index 1 and python (real programming languages) index 0, if we don’t explicitly take care of the shift in index while importing the data which was stored in matlab, same data leak will occur)
The way he suggests to debug this is to set the loss as the sum of all outputs of example i, run the backward pass all the way to the input, and ensure that you get a non-zero gradient only on the i-th input!! This proves that the information flow through the entire network for all the examples in the batch have completely independent paths and do not merge at any point!
End Notes
- All of his tips are extremely useful for daily practices while working on new projects.
- ‘Overfit on one batch’ has saved a lot of compute, especially recently for hyperparameter search.
- ‘Become one with the data’ helped me solve a bug in a network which made it underperform for more than a month.
- ‘Fix random seed’ has helped a lot to reproduce the results when the training is very unstable.
This blog along with his twitter threads on most common NN mistakes has really helped me a lot as a DL practitioner. This blog really got me interested to read more of his content, will read the others soon!