
I am a Ph.D. student in Computer Science at Georgia Tech, where I have the privilege of being advised by Prof. Judy Hoffman. Before this, I completed my M.S. at Georgia Tech and earned my B.Tech. from Manipal Institute of Technology, where I was mentored by Prof. Harish Kumar JR. I have also interned at IISc Bangalore, collaborating with Dr. Chandan Gautam and Prof. Suresh Sundaram. During my undergraduate years, I was actively involved in Project MANAS and the Research Society Manipal.
- World Models (WFM): Developing VLM-based benchmarks for automatic evaluation of world models.
- 7B Open-Source VLM: Open-vocabulary 3D scene graph generation (under review).
- SkyScenes: Synthetic aerial dataset for real-world segmentation (ECCV 2024).
- Generalist Multimodal LLM: Jointly-trained vision-audio model that reduces cross-modal interference and outperforms larger models.
My research advances vision-language models (VLMs) by extending their capabilities across modalities, spatial reasoning, and evaluation—integrating audio, enhancing spatial understanding, and enabling automatic evaluation of world models for robotic manipulation. I have also worked on syn-to-real transfer and domain generalization.
💼 I'm currently seeking research internships for 2026 — feel free to reach out if you're hiring!
📝 Recent Updates [ 🌟: Highlight | 💡: Research | 📆: Misc ]
- 🌟 Attending CVPR 2025 in Nashville!
- 🌟 Attending ECCV 2024 in Milan, Italy!
Georgia Tech published an article about our work. - 💡 Jul 1, 2024: My first first-author paper — SkyScenes: A Synthetic Dataset for Aerial Scene Understanding — accepted at ECCV 2024!
View more
- 🌟 Apr 1, 2024: Joining Georgia Tech for Ph.D. CS under Prof. Judy Hoffman (Fall 2024).
- 📆 Mar 12, 2024: Serving as a reviewer for ECCV 2024.
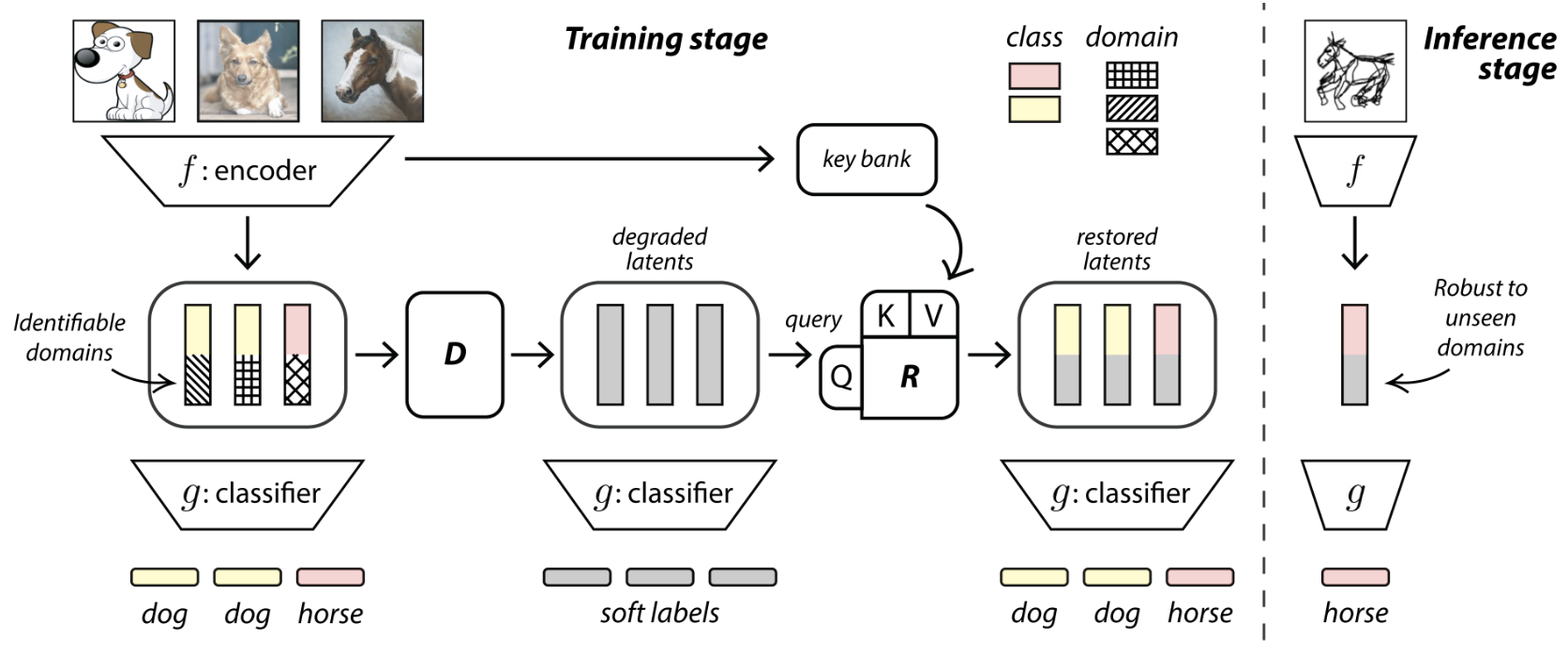
- 💡 Oct 24, 2023: My first main-conference paper — LatentDR: Improving Model Generalization Through Sample-Aware Latent Degradation and Restoration — accepted at WACV 2024!
- 🌟 Attended NeurIPS 2022 in New Orleans, LA, USA (my first in-person conference!).
- 🌟 Apr 4, 2022: Admitted to the MS CS program at Georgia Tech for Fall 2022!
📚 Publications
2024
ECCV 2024 (First first-author paper!)
Sahil Khose*, Anisha Pal*, Aayushi Agarwal*, Deepanshi*, Judy Hoffman, Prithvijit Chattopadhyay

WACV 2024 (First main-conference paper!)
Ran Liu, Sahil Khose, Jingyun Xiao, Lakshmi Sathidevi, Keerthan Ramnath, Zsolt Kira, Eva L. Dyer
2022
NeurIPS 2022 (First in-person conference!)
- Poster: Continual VQA for Disaster Response Systems at CCAI
ICML 2022 (Best Paper Award 🌟)
ACL 2022
2021
NeurIPS 2021
- Spotlight Paper 🌟: Semi-Supervised Classification and Segmentation on High Resolution Aerial Images at CCAI
- XCI-Sketch: Extraction of Color Information from Images for Generation of Colored Outlines and Sketches
Presented at: New in ML (Oral), CtrlGen, ML4CD, and DGM - Poster: A Studious Approach to Semi-Supervised Learning at ICBINB